개발/파이썬
파이썬. Pandas NaN값 처리하기
웅'jk
2022. 11. 24. 14:58
NaN 값이 존재하게 되면 데이터를 분석하는 과정에서 오류가 나타날 수 있다.
따라서 이 NaN값을 처리해줘야 한다.
1. NaN값이 있는 행을 지운다.
2. NaN값을 무언가로 대체한다.
df라는 데이터프레임은 다음과 같다

먼저 비어있는 데이터가 어디에 있는지 확인을 해야한다.
그럴때 사용하는 함수는 isna()와 notna()가 있다.
isna() : 데이터가 비어있으면 True, 비어있지 않으면 False
notna() : 데이터가 있으면 True, 비어있으면 False

그러면 이제 이 비어있는 값을 가지고 있는 행을 지워보자.
이럴때 사용하는 함수는 dropna() 함수이다.
df.dropna() # 행을 삭제한다.
행을 삭제하지 않고 다른 값으로 대체하려면 fillna()를 이용한다.

fillna 을 이용하면 평균값을 집어 넣거나 왼쪽에서 채우기, 오른쪽에서 채우기등등을 할 수 있다.
df.fillna( method = 'ffill' , axis = 0 )
비어있는 값을 행의 윗부분값을 가져와 채워넣었다.
ffill은 앞부분을 가져와서 채운다.
axis 는 행을 가져올지 열을 가져올지 정한다.
df.fillna(method='bfill' , axis = 0 )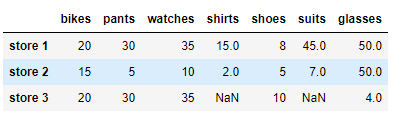
bfill은 뒷부분을 가져와 채운다.
axis 는 행을 가져올지 열을 가져올지 정한다.
또한 fillna안에 평균값이나 최소값 ,최대값을 집어넣어서 채울 수 도 있다.

이런식으로 df.mean()을 통해 각컬럼별 평균값을 비어있는 데이터에 넣어준다
마찬가지로 최대값은 df.max() 최소값은 df.min()을 통해 삽입이 가능하다.