파이썬 기초. 대소문자(upper,lower), 문자열 분리(split),슬라이싱 등
문자열에 대해서 조금 더 알아봅시다.

위 사진과 같이 파이썬에서 긴 문장(첫줄을 넘어가는)을 이용하기 위해선 ''' 또는 """ 을 이용한다.
문자와 문자를 이어 붙히는 방법은 연산자 + 을 이용한다.

공백 또한 ' ' 을 통해 삽입이 가능하다.
문자의 대소문자를 변환시키는 방법은 함수 lower(),upper()를 이용한다.

위 방식처럼 문자형변수 뒤에 .을 붙혀 사용한다.
맨앞글자만 바꾸는 capitalize(), 단어의 앞글자를 바꾸는 title()도 있다.

원하는 문자열을 분리하는 방법은 다음과 같다.

이런식으로 split()을 이용하여 분리 할 수 있다.
한부분만을 추출하는 방법은 다음과 같다.

변수뒤에 [] 을 붙히는데 이는 변수에 접근한다.
위 사진처럼 letters 변수의 3번째인 'c'에 접근하여 보여주는걸 알 수 있다.
*[2] 인 이유는 컴퓨터는 0부터 시작하는 index라는 개념으로 접근하기 때문이다.
*(사람 1,2,3,4···· , 컴퓨터 0,1,2,3····)
문자열을 조금 더 특별하게 추출하고 싶다면 [] 엑세스를 통한 접근이 가능하다.


위 사진과 같이 [] 안에 0:5 를 넣어 a 부터 e까지의 값을 추출해온 걸 알 수 있다.
*다만 주의해야 할 점은 e 의 index 값은 4 이지만 +1 을 해주어야 나온다는 점이다.
특정문자를 바꾸는 방법은 replace() 함수를 이용한다.

기존 'abcd····' 에서 'kbcd····'로 바뀐것을 알 수 있다.
문자열의 총 길이를 알고 싶다면 len()을 이용하면 된다.

위와 같이 'abc···' 알파벳 총 26개의 값이 나온걸 알 수 있다.
특정부분을 지우기위해서는 split()을 이용한다.
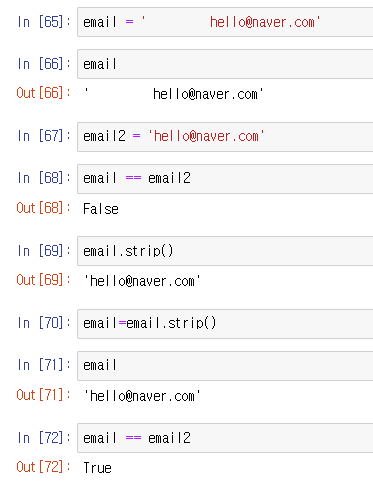
위 사진처럼 파이썬은 공백 또한 문자로 취급하기때문에 email 과 email2의 비교가 올바르지 않다고 나온다.
따라서 split 을 이용하여 공백을 빼주면 같은 값으로 나온다.
() 안에 값을 넣어주면 그부분만 삭제 된다.
문장에서 특정 단어의 index 값을 알고 싶다면 find()와 rfind()을 이용한다.

위 사진처럼 매우 긴 문장에서 index 값을 일일히 눈으로 세기 어려우니 find와 rfind을 통해 찾는다.
rfind()는 뒤에서부터 찾는다. 또한 없을 경우 -1을 출력하는데 0을 출력하지 않는 이유는 인덱스의 첫값이 0이기 때문이다.
문자열에서 특정 단어가 몇개 있는지는 count()을 이용하여 알 수 있다.

단어가 아예 없을 경우 0을 출력한다.
특정문자열의 시작과 끝이 맞는 지 여부는 startswith() 와 endswith()를 이용한다.

위 사진처럼 True 진실 , False 거짓으로 나타낸다.