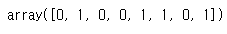개발/머신러닝
파이썬. 머신러닝 - sklearn 을 이용한 Encoding (Label , One-Hot)
웅'jk
2022. 12. 1. 11:03
먼저 sklearn 을 설치합니다.
아나콘다 프롬프트에서
$ conda install -c conda-forge scikit-learn 을 입력합니다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd데이터와 관련된 라이브러리들을 다 가져와 주세요.
그 다음 가져온 데이터를 처리해야합니다.
처리방법은
1. 분석할 데이터를 설정합니다.
2. 데이터에 NaN값이 없도록 설정합니다.

위와 같은 df 로 Purchased 의 결과를 예측하고 싶습니다.
이제 데이터에 NaN값을 처리할텐데
삭제할지, 데이터를 추가할지는 여러분들이 생각해야합니다.
저는 삭제하는 방식으로 처리하겠습니다.
df.dropna(inplace = True)자 그러면 이제 X,Y로 분리하겠습니다.
X => 분석에 이용할 데이터들
y => 예측하고 싶은 값
저는 Purchased 를 예측하고 싶으니 Y축으로
그외에 X로 두겠습니다.
X = df.loc[ : , 'Country' : 'Salary' ]
y = df['Purchased']
sorted(X['Country'].unique() )X의 Country 값이 Unique 하기때문에 이를 기준으로 정렬합니다.
그리고 이 데이터들을 학습시키기 위해서는 방정식을 이용해야하기 때문에
데이터들을 모두 숫자로 만들어야 합니다.
여기서 방식이 두가지가 나오게 됩니다.
1. Label
2. One-Hot
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer위 두가지를 import 해줍시다.
첫번째로 label 방식입니다.
encoder = LabelEncoder()
X['Country'] = encoder.fit_transform( X['Country'] )
label 방식은 unique한 값을 0,1,2 ... 등 숫자로 바꿔주게됩니다.
다만 label 방식은 unique한 데이터가 3개이상이면 학습이 떨어지므로
이를 해결하기 위한 One-Hot을 이용해야합니다.
# France Germany Spain Age Salary
# 1 0 0 44 72000
# 0 0 1 27 48000
# 0 1 0 30 54000
# 0 0 1 38 61000
# 1 0 0 35 58000
# 1 0 0 48 79000
# 0 1 0 50 83000
# 1 0 0 37 67000
# 위 처럼 만들기 위해서
ct = ColumnTransformer( [ ( 'encoder', OneHotEncoder() , [0] ) ] ,
remainder= 'passthrough' )
# 튜플에 [0]은 컬럼을 의미한다 , 지금같은 경우는 country 이기때문에 첫번째 (0)을 의미
#remainder = 'passthrough' ? One-Hot 이 아닌 컬럼은 그냥 냅두라는 뜻.
ct.fit_transform( X )
X 는 이렇게 완료가 되었고
y 또한 Yes, No 이기 때문에 Y 또한 숫자로 만들어야합니다.
y.unique() # y의 유니크값 확인
sorted(y.unique()) # y를 정렬
encoder_y = LabelEncoder() # y용 label 인코더
y = encoder_y.fit_transform(y) # y에 바뀐 결과 저장