이번에는 정수값이 아닌 실수값을 가져올때는
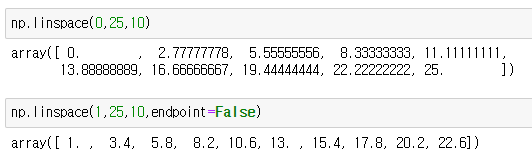
linspace ( 시작,끝,개수) 를 이용하여 실수값을 가져와 1차원 배열로 만들어준다.
그러면 다음과 같은 1차원 벡터값을 2차원 행렬로 만들려면 어떻게 해야할까?
먼저 1차원 배열을 만들어보자.

x 는 2부터 10까지 저장되어있는 1차원 벡터이다.

위 사진처럼 shape , ndim 을 통해 1차원인 것을 확인했다.

위사진은 대문자 X에 소문자x.reshape(3,3)을 저장한 것을 알수 있고
X를 출력하니 위 사진처럼 나왔다.

모양과 차원을 확인해보니 2차원 행렬 3x3인걸 알 수 있다.
다만 중요한 점은
x = [55,15,10,2,15,55,79,97,78,81] 인 값이 있는 벡터라고 하자.
X = x의 값이 5열 2행으로 reshape되어있는 행렬이다.

위 사진처럼 대문자 X를 다시 reshape 하여 1,10 으로 만들었다.
출력결과만 보면 벡터처럼 보이나 사실 행렬이므로 헷갈려서는 안된다.
이 결과를 같게 만들려면

위 사진처럼 , 가 아닌 그냥 10 을 넣어주면 된다.
이렇게 reshape를 통해 1차원을 2차원으로, 반대로 2차원을 1차원으로 나타낼 수 있다.
이번에는 이 데이터를 random 값으로 배열을 만들어보자.
numpy에서는 기본적으로 random을 지원하기 때문에 따로 random 을 import 하여
복잡하게 배열을 만들 필요가 없다.

위 사진처럼 np.random.random()을 이용하여 만들 수 있다.
정수로 만들고 싶다면 randint(start,stop,size=shape) 를 이용하면 된다.

위 사진처럼 size 값에 정수값을 넣으면 1차원 백터가
(3,4) 처럼 모양을 지정해서 넣어주면 2차원 행렬 값이 나오게 된다.
지난 시간에 여러가지 기능으로
max() -> 최대값 , min() -> 최소값
sum() -> 전체합 , mean() -> 전체 평균
std() -> 표준 편차를 알아보았는데 이번에는 2차원 행렬에서
각각의 행,열 의 값을 알아보자.
(추가로 중앙값은 np.median(배열) 을 통해 알수 있다.)
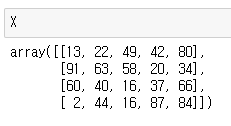
X는 위 사진처럼 4x5 행렬이다.


행렬에서는 axis 라는 키워드를 통해 알 수 있는데
axis = 1 은 행 , axis = 0 은 열 을 의마하게 된다.
이번에는 다차원 배열을 접근하는 방법을 알아봅시다.
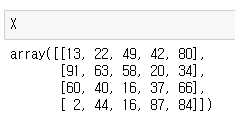
X = 다음과 같은 값을 가지고 있는 행렬입니다.
이 X의 값중 58을 접근해봅시다.
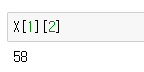
이런식으로 접근이 가능합니다.
조금 더 쉬운 방법으로는 [행,열]을 통해 접근이 가능합니다.

예를 통해 알아봅시다.
X의 값중 [63,58,20],[40,16,37]을 가져와 봅시다.
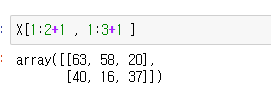
이런식으로 슬라이싱을 통해 가져오게 되며
앞쪽 행 슬라이싱으로 두번째 행부터 세번째행까지를
, 을 기준으로 오른쪽 열 슬라이싱은 두번째 열 부터 네번재 열을 가져오게 됩니다.
그럼 이번에는 위 X에서 3번째 열을 가져와 봅시다.
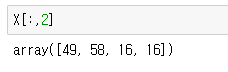
이런식으로 가져오게 됩니다.
다만 주의할점은 행부분이 빈칸이면 구조적으로 접근이 안됩니다.
(행 -> 열 순으로 접근해야한다.)
이번에는 첫번째 행과 세번째 행을 가져와 봅시다.

이런식으로 슬라이싱뿐만 아니라 리스트를 통해 행값 또는 열값을 지정해줄 수 있습니다.
다만 이렇게 슬라이싱으로 가져온 값은 한가지 문제점 이 있습니다.
바로 데이터를 복사가 아닌 참조로 가져오기 때문입니다.
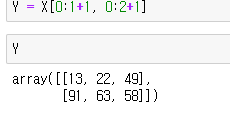
X의 값을 슬라이싱해서 Y로 가져왔습니다.
이제 이 Y의 값을 바꿔봅시다.
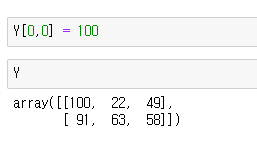
이런식으로 첫번째 값을 100으로 바꿨습니다.
X의 값을 한번 볼까요?

X 또한 처음값이 100으로 바뀐 것을 알 수 있습니다.
이를 해결하기 위해서는 copy()함수를 이용하여 복사해온 뒤 값을 바꿔주셔야합니다.

이번에는 중복된 값을 제거해주는 함수 unique()를 알아봅시다.

page_view list에는 중복된 수가 여러개 저장되어 있습니다.
이러한 중복을 없애고 싶다면 우리는 set 집합을 통해 없앨 수 있었습니다.
배열에서 중복된 값을 없애고 싶다면 unique() 함수를 통해 없앨 수 있습니다.
다음은 boolean 연산을 이용하여 데이터를 가져와봅시다.

X의 데이터가 위 사진처럼 있고 80보다 큰 데이터가 몇개인지 가져올려고 합니다.
X>80 은 80보다 큰 값들은 True(=1), 작은값은 False(=0)으로 알려줍니다.
여기서 sum()을 통해 개수를 알 수 있는데 이는 0과 1밖에 없기때문에 다 더한값이
갯수가 되기 때문입니다.
데이터를 가져오기 위해서는 엑세스를 이용해야하기 때문에 엑세스안에 조건을 넣어
가져올 수 있습니다
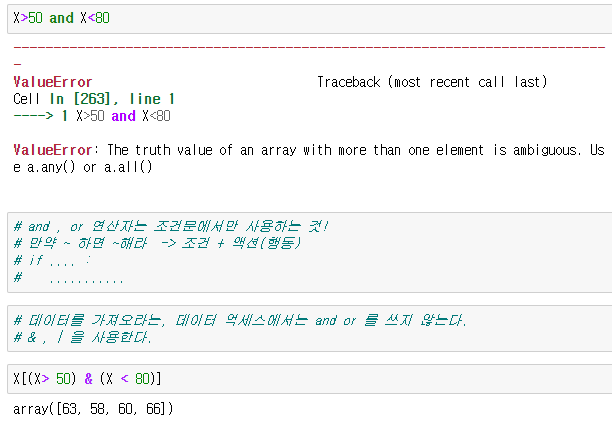
다만 여기서 주의하실점은 만약 조건이 2개 이상인경우는 &,| 을 사용합니다
조건문에서 사용하던 and , or 키워드는 조건문에서만 사용이 가능하므로
이점 주의하시길 바랍니다.
'개발 > 파이썬' 카테고리의 다른 글
| 파이썬. Pandas Dataframe 생성,접근,NaN (0) | 2022.11.23 |
|---|---|
| 파이썬. Pandas 생성, 접근,연산 (0) | 2022.11.23 |
| 파이썬. Numpy - 기본개념, 벡터와 행렬 (0) | 2022.11.22 |
| 파이썬. 메모리 (0) | 2022.11.22 |
| 파이썬. library란? random, datetime,time,parse 등등 (0) | 2022.11.22 |