import pandas as pd
# We create a dictionary of Pandas Series
items = {'Bob' : pd.Series(data = [245, 25, 55], index = ['bike', 'pants', 'watch']),
'Alice' : pd.Series(data = [40, 110, 500, 45], index = ['book', 'glasses', 'bike', 'pants'])}위 와 같은 items 딕셔너리가 있습니다.
이 items 를 이용해 DataFrame 을 만들어보고 데이터에 접근하는 방법까지 알아보겠습니다.
df = pd.DataFrame(data = items)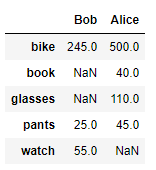
출력하시면 위와 같은 값을 얻을 수 있습니다.
여기서 bike,book,glasses,pants,watch 의 값은 index
Bob, Alice 는 colum
안쪽의 데이터는 values를 의미합니다.
df.index
df.columns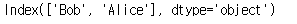
df.values
df.shape
df.ndim
df.size이 데이터의 모양,차원,크기 등을 알 수 있는데
type는 작동하지 않는다.
2차원 값들이기때문에 각 컬럼별 데이터가 다 다르기 때문이다.
그대신 info()를 이용할 수 있다.
df.info()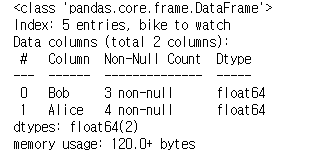
NaN은 해당항목에 값이 없음을 뜻한다.
위에서도 Bob의 book, glasses, Alice의 watch 처럼 값이 존재하지 않을 경우
NaN으로 표기해준다.
이 DataFrame 또한 index를 지정해줄 수 있다.
# We create a list of Python dictionaries
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5}]df = pd.DataFrame(data = items2 , index=['store 1','store 2'])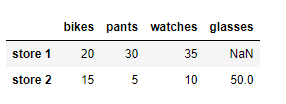
위 dataframe 에서 데이터를 접근하는 방법을 알아보자.
'bikes' , 'glasses' 의 컬럼의 데이터들을 가져와 보자
df[['bikes','glasses']]
위와 같은 식으로 데이터를 가져올 수 있다.
즉 컬럼의 데이터는 []로 접근이 가능하다.
store 2 에서 bikes, watches 의 데이터를 가져와보자
df.loc['store 2',['pants','watches']]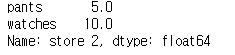
이런식으로 loc를 이용하면 행,열로 데이터 접근이 가능하다.
이번에는 컴퓨터의 인덱스 값을 이용한 iloc를 이용해보자.
store 2 에서 bikes,watches,glasses의 데이터를 가져오세요
df.iloc[0,[0,2,3]]
loc와 iloc는 우리가 설정한 인덱스를 사용하냐, 컴퓨터의 인덱스를 사용하냐의 차이다.
'개발 > 파이썬' 카테고리의 다른 글
| 파이썬.Pandas DataFrame 행,열 삭제하기,인덱스설정,이름변경 (0) | 2022.11.24 |
|---|---|
| 파이썬. Pandas DataFrame 데이터 수정, 컬럼 추가,행 추가 (0) | 2022.11.24 |
| 파이썬. Pandas 생성, 접근,연산 (0) | 2022.11.23 |
| 파이썬. Numpy - random(),randint(),슬라이싱,조건식,copy(),unique() (0) | 2022.11.23 |
| 파이썬. Numpy - 기본개념, 벡터와 행렬 (0) | 2022.11.22 |