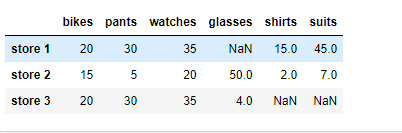
DataFrame df 는 위와 같은 값을 가지고 있습니다.
DataFrame 에서 행렬삭제는 drop()을 이용합니다.
store 2 의 값을 삭제하고 싶습니다.
df.drop('store 2' , axis=0 )
실행하면 위 사진처럼 출력이 됩니다.
이번에는 glasses 컬럼을 삭제해봅시다.
df.drop('glasses' , axis= 1 )이런식으로 drop('삭제할 컬럼or행 이름' , axis = 0( =행) , 1(=열) ) 을 입력하면 됩니다.
인덱스의 이름을 변경하려면 rename() 을 이용합니다.
store 3 의 이름을 last store로 바꿔봅시다.
df.rename(index={'store 3' : 'last store'} )
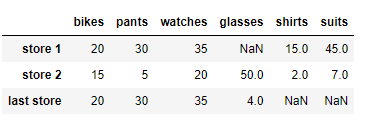
이번에는 컬럼의 이름을 변경해봅시다.
df.rename(columns={'bikes' : 'hat' , 'suits' : 'shoes '})
이런식으로 index가 아닌 columns 라는 속성으로 바꿀 수 있다.
새로운 컬럼을 추가해서 그 값을 인덱스로 설정해보자
df['name'] = ['A','B','C']
df.set_index('name' , inplace=True)
name 은 a,b,c 값을 가진 컬럼이고 이값을 set_index를 통해 설정해주면 된다
여기서 inplace는 메모리에 저장을 허용할건지 아닌지를 결정한다.
그럼 초기화는 어떻게 할까.?
reset_index() 함수로 초기화 하면된다.
df.reset_index(inplace=True)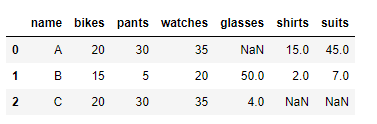
'개발 > 파이썬' 카테고리의 다른 글
| 파이썬. Pandas NaN값 처리하기 (0) | 2022.11.24 |
|---|---|
| 파이썬. CSV 파일 읽어오기 , describe , info (0) | 2022.11.24 |
| 파이썬. Pandas DataFrame 데이터 수정, 컬럼 추가,행 추가 (0) | 2022.11.24 |
| 파이썬. Pandas Dataframe 생성,접근,NaN (0) | 2022.11.23 |
| 파이썬. Pandas 생성, 접근,연산 (0) | 2022.11.23 |